We have seen that XML is a plain text Data Format used to store and send/receive information in a structured way. However, the XML document is not static data. Many times you will need to read, change, or extract information from an XML file. But how do you do it? How do programs work with the XML content? That’s where the XML Document Object Model (DOM) comes in.
Why do we need the XML DOM?
The Document Object Model (DOM) represents an XML document as a logical tree structure. This allows programmatic access to the tree, enabling programming languages to search and modify the structure or content of a document.
Let's look at the following XML document that we are going to use as an example. The document is just plain text. So how do you tell a Python script to change the interface's IP address from 10.1.1.1 to 192.168.1.1? Do you edit the document as plain text the same way you edit text files?
<?xml version="1.0" encoding="UTF-8"?>
<interfaces>
<interface name="GigabitEthernet0/0">
<ipAddress>10.1.1.1</ipAddress>
<netMask>255.255.255.0</netMask>
<speed>1000</speed>
<duplex>full</duplex>
</interface>
...
</interfaces>Of course, you don't edit XML files as plain text - deleting and replacing text characters one-by-one as you type text on a computer. XML files follow strict rules for structure, nesting, and syntax. A small mistake — like deleting a tag or misplacing a quote — can make the whole file invalid. Programs that read XML need the data to be well-formed, so they can’t work with a broken structure.
That’s why we use the DOM (Document Object Model).
The DOM converts the XML file into a tree of objects that keeps the structure intact. Each element, attribute, and text becomes a node that a program can read, change, or delete safely. For example, the following diagram represents the XML document we used above as a tree. Notice that the information is the same but represented as a tree structure.

Instead of editing plain text, the program works through the DOM tree. This ensures that all elements stay properly nested and the XML remains valid after any changes.
Working with large XML files with an unknown structure
To really understand why we need the Document Object Model (DOM), consider the example shown below. Let's imagine that you want to extract a router's Gig0/1 IP address using a Python script that reads the router's entire configuration in XML format (which is practically possible). However, you don't know the document structure. You don't know the tags and how deep the interface IP address element is in the document. How would you get to the exact information you want?

Without the DOM tree, your only option is to download the entire router configuration in XML format and manually search through the document to find the information you need. But the document is huge, and we talk about manual work here. In the network automation context, this is not what you want, right?
Now consider the following animated example shown below. The Document Object Model (DOM) is a cross-platform and language-independent programming interface for accessing and manipulating XML documents. You can use Python to walk through the tree and find the information you need. You don't need to know the entire document structure.
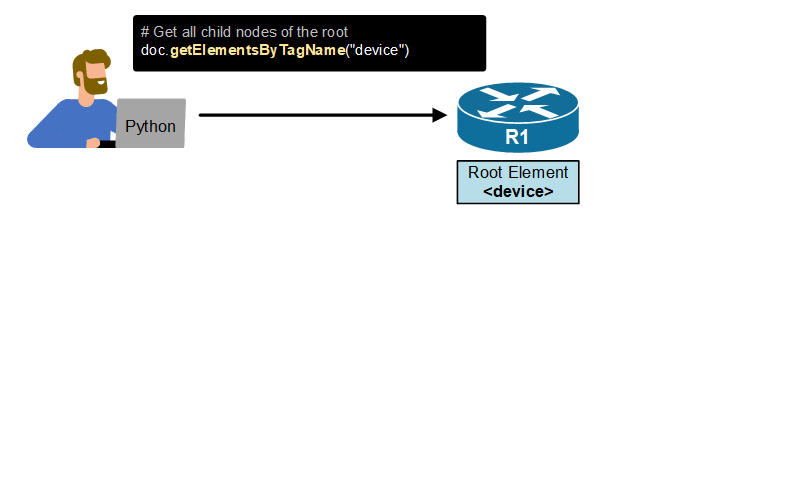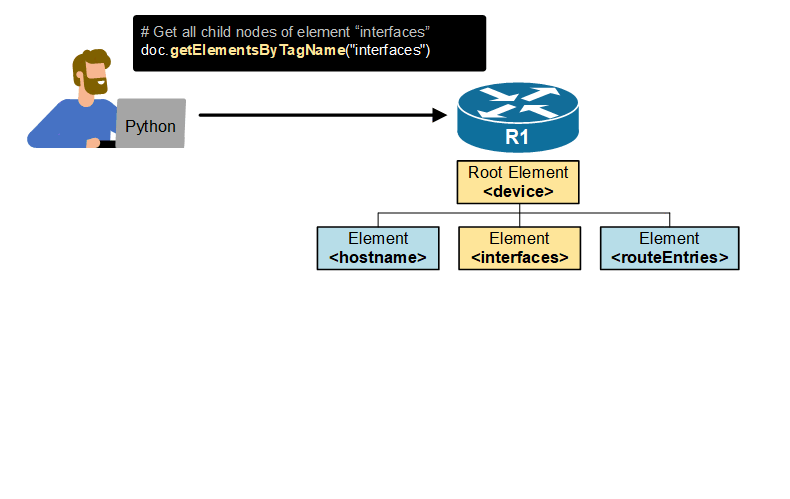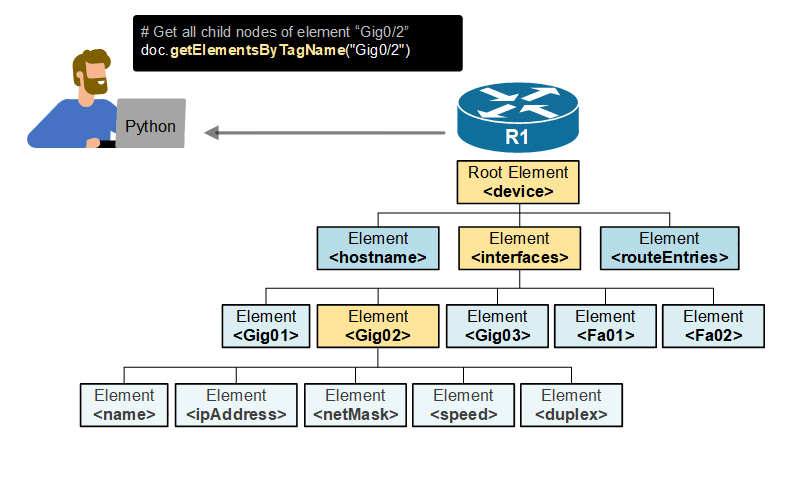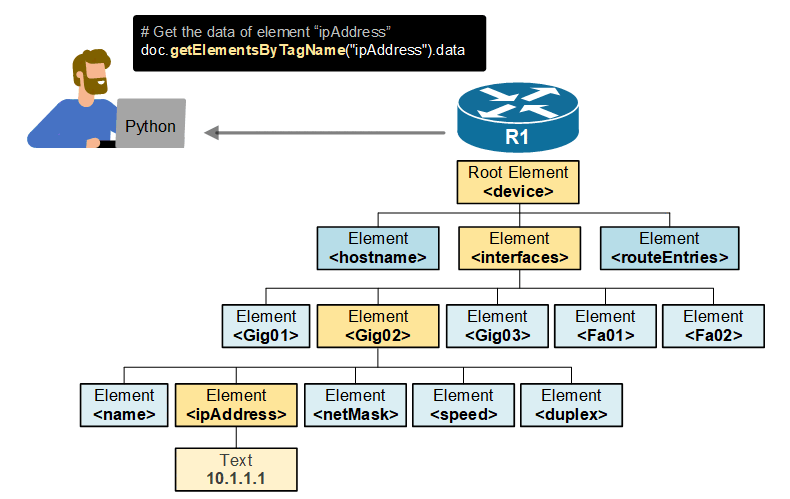
Keep in mind that this example is simplified and exaggerated. It is designed to illustrate why we need the DOM tree in the first place.
In short, representing an XML document as a DOM tree is very useful for the following reasons:
- Structured access – It turns the XML file into a structured tree, which is easy to search and modify.
- Language independence – The DOM is a standard interface. It works the same way in many programming languages.
- Dynamic updates – You can change parts of an XML document without reloading the whole file.
- Automation – Many network management systems use XML-based APIs. DOM makes it possible to parse and change device configuration automatically.
How does the Document Object Model work?
We can summarize how the Document Object Model works into three main functions:
- Func 1: It reads the XML text and turns it into a tree of nodes.
- Func 2: It lets programs navigate, read, and edit elements safely.
- Func 3. It keeps the XML structure correct and consistent.
Let's walk through each function in more detail using a simple example.
Nodes
First, remember that the XML Document Object Model turns everything in an XML document into a node:
- The entire document is a document node
- Every XML element is an element node
- The text in the XML elements is text nodes
- Every attribute is an attribute node
- Comments are comment nodes
The DOM parses the XML text
Let's say we have the XML plain text below. Notice that it represents two interfaces - GigabitEthernet0/0 and FastEthernet0/1/0.
<?xml version="1.0" encoding="UTF-8"?>
<interfaces>
<interface name="GigabitEthernet0/0">
<ipAddress>10.1.1.1</ipAddress>
<netMask>255.255.255.0</netMask>
<speed>1000</speed>
<duplex>full</duplex>
</interface>
<interface name="FastEthernet0/1/0">
<ipAddress>192.168.1.1</ipAddress>
<netMask>255.255.255.0</netMask>
<speed>100</speed>
<duplex>full</duplex>
</interface>
</interfaces>When a program loads this XML with a DOM parser, it reads the text and builds a tree structure in memory, which looks like this:
interfaces
├── interface (name="GigabitEthernet0/0")
│ ├── ipAddress: 10.1.1.1
│ ├── netMask: 255.255.255.0
│ ├── speed: 1000
│ └── duplex: full
│
└── interface (name="FastEthernet0/1/0")
├── ipAddress: 192.168.1.1
├── netMask: 255.255.255.0
├── speed: 100
└── duplex: fullUsing the DOM tree
Once the tree is built, the program can move through it. It can go from parent to child, from one node to another, or read data from any element. For example, using Python's dom module, you can parse the document, as shown in the code block below:
# Import the minidom module from Python's XML library
from xml.dom import minidom
# Parse (read) the XML file and load it into a DOM object
doc = minidom.parse("interfaces.xml")
# Get the root element of the XML document (the top-level tag)
root = doc.documentElementThen you can list all interface elements using the following code:
# finds all <interface> elements
interfaces = doc.getElementsByTagName("interface")
# reads the name attribute
for i in interfaces:
print("Interface:", i.getAttribute("name"))It output:
Interface: GigabitEthernet0/0
Interface: FastEthernet0/1/0Full Content Access is for Subscribed Users Only...
- Learn any CCNA, CCIE or Network Automation topic with animated explanation.
- We focus on simplicity. Networking tutorials and examples written in simple, understandable language.